I attended a weekly meetup organized by NUS Hackers last Friday, and on that day, the speaker was a professor from my very own university itself, Dr. John L. Gustafson. He talked about the problems of the currently widely use (if not de facto standard) IEEE 754 floating point representation, which he said the usage of it is dangerous, calling it "weapons of math destruction". He touched on some very interesting points, such as why they designed it such that it has a huge number of exponent bits, the existence of too many representation of NaN, how it didn't fulfil even the most basic mathematical properties such as commutativity, associativity, and distributivity. A little note on commutativity, he mentioned that compilers nowadays "solved" the commutativity problem by always doing arithmetic operation of "smaller <operand> higher", whether you write the higher or smaller number as the first argument, which I think is funny but at least it works. He also went on to tell stories of when IEEE 754 caused some accidents and mishaps to happen due to its inaccuracie, some are plain funny but others are somewhat tragic.
He went on to explain to us his proposed float representation, which he calls "posits" and "valids". Posits are very similar in terms of purpose to IEEE 754; the difference is just their ways of representing numbers. Valids are for those mathematicians who need precise, accurate answers and want to be sure to know if the number the floating point representation represent is not actually accurate; something the currently available representations cannot do.
I found the representation system he proposed to be mindblowing. In a nutshell, it uses much fewer bits to represent the same number as compared to its IEEE 754 equivalent, but with a much higher precision. Another interesting point is that it can represent integers and low decimal points floats very precisely, so there's no way you can end up with 0.1+0.1 != 0.2; 1 + 0 = 1.0...0234... and so on. There is also only one way to represent 0, unlike +0 and -0 on IEEE 754. NaN is also eliminated, leaving much more bits to be used to allow higher precision. It may sound too good to be true to some, and to be honest, I haven't seen it in action, nor do I understand fully how it works, but from the high level overview I understand from the talk, it sounds really promising.
For those of you who are interested in his floating point representation proposal, NUS Hackers had very kindly shared the talk slides on Google Drive, so go ahead and take a look! Let me know if the link is down so I can request for the new link from them!
Also, you can get a more comprehensive explanation on the floating point representation he is working on in his book, The End of Error. However, note that the representation he talked about in the book is "outdated". The one in the slides I shared with you earlier is his work which was just completed a couple of months ago, so there might be some discrepancies with what I have said and what you read on the book itself.
I really hope his proposal will pass the IEEE committee and it will be in the mainstream soon. I shall end off this post using Dr. Gustafson's own words, taken from the slides itself. Let's "Make Single Precision Great Again".
Monday, March 20, 2017
Monday, February 27, 2017
Setting PostgreSQL Environment Variables on Windows (pg_env.bat)?
I needed to have postgres commands available in the command line, and found this script called pg_env.bat when I was trying to add the bin directory into my
PATH environment variables. Running it from the command line does not produce any error message, and the postgres commands work fine too, however when I was running a make script it throws an error like this (truncated, I lost the actual, full error message): Error [WinError 2] The system cannot find the file specified while executing command git config --get-regexp remote\..*\.url
Turns out the answer is that I need to edit the bat script and remove the quotation marks on the line where it is adding it to
PATH (@SET PATH="...";%PATH%). Remove both of the " quotation marks and it should work.
Turned out it was reported 5 years ago and for some reason they have not acted on it. I hope they fix it soon.
Something interesting to know, I found another thread that requested them to do the exact opposite, so I do not know which one supposed to be correct, but in any case, without quotes
" works in my case.
Hopefully this helps anyone else facing the same issue!
Sunday, March 27, 2016
Comparing School-Based (Internal) and External Open-source Projects
This post is written for the purpose of fulfilling requirement for the Facebook Open Academy course I take in NUS.
For almost one semester now, I have been working on two open-source projects that are quite different in nature. The first one is an open-source project being used by developers who wanted to use WebSocket in their web application, and maintained by a handful of developers from different parts of the world; Socket.IO. The other one is also an open-source project, but it is being developed mainly by students (and a large number of them in certain period), and with lesser variety (and probably quantity as well) of users; PowerPointLabs.
For almost one semester now, I have been working on two open-source projects that are quite different in nature. The first one is an open-source project being used by developers who wanted to use WebSocket in their web application, and maintained by a handful of developers from different parts of the world; Socket.IO. The other one is also an open-source project, but it is being developed mainly by students (and a large number of them in certain period), and with lesser variety (and probably quantity as well) of users; PowerPointLabs.
Organization
Being school-based project, I found PowerPointLabs to be more organized in the way it writes the guide for contributing. This does not come as a surprise, as most of the developers are actually students who have little or no prior experience contributing to an open-source project. In contrast, guide for contributing to Socket.IO is practically non-existent; the only guide they provided in the website is the guide on how to use the Socket.IO itself, not how to contribute to it. This is also very normal because being a library, most developers who visit the website/Github page are probably intending to use the library instead of contributing to it.
Also, getting Pull Requests to be merged into school-based open-source project is somewhat more difficult than getting the same done in external projects. This is because for the school-based one, strict review is carried out to instil good coding practice to the students. On the other hand, most open-source project out there are not very particular about coding practice, as long as it is not detrimental to the functionalities of the project. Moreover, most people who contributed to crucial parts of the project are most probably experienced developers anyway so there is no need to have such a strict review system. If the project owner/maintainer is particular about certain coding standards, he/she can always incorporate linting to the project (which is what I did for the course).
Ease of Contributing
Ease of contributing is not quite the same as ease of getting pull request to be merged; ease of contributing here refers to having something to contribute upon in the first place.
Contributing to internal open-source projects are easy. This is because the projects are there with exactly that purpose; for students to contribute to it.
Contributing to external open-source projects are much more difficult as most of such projects are already mature. Usually contributions from external developers (not the project's core team) is in the form of bugfixes, which is arguably more difficult to do than implementing new features for internal projects. This is because the developers of the external open-source projects are usually experienced developers and thus bugs in their code are usually mistakes that can not be easily fixed.
This is in contrast to internal projects where non-critical bugs are left on purpose so that the students can familiarize themselves with the code base; there is no such a thing in external open-source projects.
Rate of Development
Most open-source projects out there usually have a relatively longer release cycle compared to school-based open-source projects. This is because most open-source project contributors have full-time jobs or other commitments, and thus cannot afford to work on the open-source project full time. This sometimes results in long outstanding pull requests (especially if it is not a critical bugfix). Also, the project's main developers come from different parts of the world, and thus the different time zones the different developers live in may impact the rate of development as different developers are awake on different timings.
On the other hand, students may be considered as working on the project full-time and thus the release cycle tends to be much shorter, and I have yet to encounter an unattended long, outstanding pull request in PowerPointLabs or any other NUS projects unless if it is the student sending the pull request ignoring the feedback from the core developer team.
Suggestions for Improvement
There is always a room for improvements, be it for the internal school-based projects or the external ones.
For the external projects, it may be good to have more than one person to be in-charge of a project so as to prevent long outstanding pull request if the person in-charge is busy with other commitments. This is especially important if the project is listed on university programmes such as Facebook Open Academy or Google Summer of Code, when the rate of development will increase tremendously due to the extra manpower during the period.
For the internal projects, I feel that there is not much suggestion I can provide in terms of workflow; I think the current workflow works well to serve its purpose. However, I have the feeling that school-based projects have features that is not very well-polished. It could be better to focus the effort on polishing existing features first before implementing new ones. I think doing a product that do a few things but doing it well is better than a product that can do a lot of things but not good at any of it.
Conclusion and Closing
In conclusion, I think internal (school-based) open-source projects are much more organized in terms of contribution guide, are easier to contribute to, and are faster in release cycle than external open-source projects. External projects can do better by having multiple people in charge of the development so that they can fill in the other person if he/she is busy with other commitments. Internal projects may try to focus more on polishing existing features, which I think is the better approach, instead of keep releasing new features.
Sunday, March 20, 2016
Git vs Mercurial workflow: History, Commit, and Branching
This is going to be another Git vs Mercurial post, which is already widely available on the cyberspace (this, this, this… I can go on) but I am writing another one nevertheless because I feel that many of such posts are written with so much hatred (especially those that is in favour of Git, unfortunately). So this post is going to be one of those Git vs Hg post where the author is in favour of Git but not trying to bash Mercurial (too hard, hopefully). Also, I am going to focus on the similarity and difference in workflow instead of functionalities, though differences in workflow will inevitably also bring about some differences in features into the discussion, but I will try to minimize it.
Note: This post assumes some basic knowledge of Git and Mercurial commands.
Attitude towards commit/changeset history
In Mercurial, history are “sacred” and not to be manipulated. The only command that a user can do out-of-the-box that can edit history is only
hg revert, which only removes the last changeset. To manipulate further down the history, Mercurial extensions are available, but they are tedious to use and confusing at best (speaking from my experience using Mercurial on a project 2 years ago). For Git users like myself, this is a huge annoyance as we are used to “fixing” history to make it look nicer and more easily traceable in the future.
Git, on the other hand, allows users to manipulate commit history to their hearts’ content. In fact, it seems to be encouraged, evident from how easy it is to do so (
git rebase, git rebase -i, git push -f, and many other relatively short commands that changes history). This allows the creation of a better-looking, more linear commit history. However, inexperienced user may break the entire repo with it. Luckily, Git keeps track of everything and one can go back to the exact state before the accident happened (provided it didn’t happen more than a month ago; plenty of time to realize something bad has happened, if you ask me).Commit workflow
In Git, there are 4 states a file can be in; untracked, unstaged, staged, and committed. To move a file (or more precisely, a change/modification) from untracked or unstaged to the staged state, use
git addand to move to the committed stage, use git commit.
In comparison, in Mercurial there are only 3 states; untracked, uncommitted and committed. To move a file from untracked to uncommitted, use
hg add and to commit use hg commit.
The difference here is that in Git, the user can choose not to commit all changes in the working directory (using
git add <filename> or git add --patch, for example). This is useful to make a commit atomic (which is part of Git’s or any version control system’s best practices), or if you have finished work in some files but not in others. In contrast, in Mercurial, there is no staging state and hg commitautomatically commits all changes in the working directory. If you came from Git background like myself, you will find yourself repeatedly committing unfinished work, and what’s worse, it is difficult to fix the messy history due to that mistake! That was the pain I personally went through in the Mercurial project I worked on 2 years ago.
There are Mercurial extension that mimics this Git behavior, but I have not used it personally so I cannot comment on it. However, from what I have found on the Internet, it seems to be a decent replacement for users coming from Git background using Mercurial.
Branching
In Git, there is only one way to branch (though there are a few commands to create a new branch but that’s beside the point). Any divergence in commit history is a branch, and the name of the branch is namespaced according to which repository the branch originates from.
For example, if I have a branch called
test which tracks a remote branch with the same name, if at some point in time my local branch and the remote branch diverges, when it is being merged, the remote one will be called remote/test. There is no other “branching” method.
In Mercurial, there are at least 3 ways of branching.
The first one is a clone-branch. This seems to be the initially-intended branching workflow of Mercurial, evident from the “local-cloning-optimization” feature they have called “hardlink” which makes cloning from a local repo faster. This, however, is not a feasible branching workflow for certain types of projects where dependencies need to be downloaded separately (through
npm or pip, for example) for each repo.
The second branching workflow that Mercurial supports is called named-branch. It is quite similar to Git branch in that one can
update (or checkout in Git terminology) to the latest commit on that branch. In Mercurial, however, named-branch is not a light-weight pointer to a HEAD just like in Git, but is something that is included in a changeset’s (or commit, in Git terminology) meta-data. There are some implications that people from Git’s world don’t really like (such as cluttering the revision history with short-lived branches and needing to “close” a branch with an extranous commit). On the other hand, it could be useful when tracing the history. But then again I have worked with Git for quite a while and I have never encountered a problem where I need to know the name of the branch a commit was from, so the usefulness is questionable.
The last branching workflow that Mercurial has is bookmarks. This is (claimed to be) the Git-branching equivalent in Mercurial. However, having used it in one of my projects 2 years ago, I find that they are not quite the same. In fact, I find that Mercurial’s named branch is more similar to Git branch than Mercurial bookmark is simiar to Git branch. In Git, you are always working on a branch, so whenever you commit, you commit to a branch and other people who pull your work knows that your commit belong to a certain branch. In contrast, you are not always on a bookmark in Mercurial, and thus people may accidentally committed when he is not on a bookmark, requiring the user to manually move thebookmark to the intended changeset. Also, when sending a pull request, the name of the bookmark is not shown. Instead, the hash of the changeset is written as the “branch name”. This makes me doubt the claim that bookmark is really the Mercurial equivalent of Git branch.
Arguably, there is another Mercurial branching workflow, which is simply not to do anything about it. If there is a divergence from a certain changeset, simply don’t do anything about it. Users can refer to a “branch” by the hash or revision number of the tip of the “branch” he/she intends to work on. This is good for quick fixes, but is not suitable for development branch as it will be difficult to keep track which “branch” is doing what. I am unsure if it is one of the intended way to use Mercurial.
Conclusion on Branching
In my opinion, Git’s branch workflow is better, as it is more consistent (i.e. there is only one way to do it). If I were to use Mercurial, though, I would probably use the named-branch workflow as it is much more manageable than all the other Mercurial branch workflow.
One may argue that Git also has some divergence in terms of branch workflow, namely "to
merge or torebase". In my opinion, it is actually what makes Git great; you have the option whether to preserve history as it is or to make a cleaner, nice-looking history. In contrast, Mercurial’s different branch workflows are not really “options” but rather inconsistency on Mercurial’s default development workflow. I mean, I can’t really think of the benefit of using the clone-branch workflow, or bookmark-branch workflow over any of the other options. But then again, maybe I have not used Mercurial enough to discover the different benefits and disadvantage of the different ways of branching in Mercurial.
Just to reiterate, I wrote a comparison of two of the most popular distributed version control systems in terms of their attitudes towards history, commit workflow, and branching. I found that Git’s way of doing things to be better than that of Mercurial’s because of the flexibility and consistency that Git provides.
Feel free to point out any mistakes in my post. I have not used Mercurial for quite a while so probably some information is outdated, but I did some research before posting this so it should not be too outdated.
Other references not linked on the post itself:
- Source on the different Mercurial branch workflows here.
- http://blogs.atlassian.com/2012/02/mercurial-vs-git-why-mercurial/
- http://blogs.atlassian.com/2012/03/git-vs-mercurial-why-git/
Friday, March 4, 2016
Git tips and best practices
This post is intended for you developers who have just started using Git, or perhaps have been using it for a while, but have not been using it optimally. Here are some tips to level up your Git mastery; to make your project more manageable and organised.
Note that some of the tips here are in the context of working with Git and Github, but Github can always be replaced with any other repository hosting website like Gitlab, Bitbucket etc.
Another note: if your team already has a Git policy, please do obey them if it is in confict with whatever I have here below. This is by no means is the only correct way to do things, but it is what works best for me so far.
Another note: if your team already has a Git policy, please do obey them if it is in confict with whatever I have here below. This is by no means is the only correct way to do things, but it is what works best for me so far.
Tips for Novice Users
Always pull (or even better, fetch) before committing locally
This is to prevent too many “Merge remote tracking branch …” commits which are not very descriptive and give more work to people who are investigating commit history , as they need to open the commit to know what changes instead of by just reading the commit message.
Just to give a brief explanation, this happens because the branch in your local repo and the remote repo has diverged. Let’s say the last commit on the branch when you were working on it was
A and then you go ahead and add another commit B. However, someone else actually already pushed a commit C to the same branch. Now if you try to push your local changes, the server (eg Github) will reject it because for all it knows, the next commit after A is C, however what you have after A is B, which is inconsistent with what the server has. If you do a git pull, because Git cannot decide which commit should come first before the other, it will just create an extra merge commit. (I will add a diagram to show this more clearly)fetch is potentially better if you are working on a shared feature branch that might be rebased once in a while. This is to notify you if the branch is being push --forced and you should handle it accordingly (hint: not pull) by either deleting the local branch and checkout the new one, or git reset --hard <remotename>/<branchname>. Make sure you are on the right branch before you do the latter!Each commit should be as atomic as possible
The most common bad practice of someone who just started off using any version control system is that they think it is just another way of saving and backing up their work to the cloud. While this is not entirely wrong, it leads to weird commit messages as the commit author has not actually finished what he is doing; it was just a commit to “save” his work.
A slightly better bad practice is that they commit only when the work they intended to do is done, and write what they did as the commit message accordingly. However there are more changes in the commit than what is described in the message. It may catch people who investigate commit history off guard because they did not realize some functionalities are incorporated into the branch. It also prevents the use of
cherry-pick. Of course, one can use merge in place of cherry-pick but as said earlier, merge commit messages are not very meaningful and so it is better to do cherry-pick.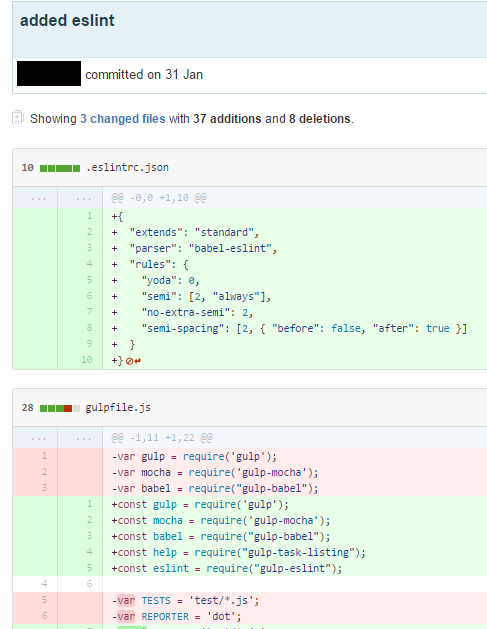 |
| Commit message is "added eslint" but there are some refactoring too |
There are many other benefits of committing atomically; another example is that it makes
rebase -imuch easier. If you are still a beginner, you most probably won’t be doing a lot of rebase and cherry-pick (if at all) but your more experienced teammates will thank you for this, trust me.If you are collaborating on a shared repo: always create a feature branch
No matter how small the team is, how small the project is, how small the changes you intended to make;
master branch should never be touched except for merging from feature branches or syncing with upstream repo (if you are forking another repo).Aliases
Sometimes writing git commands that is relatively long (such as
checkout, or log with some prettify options, etc) is just plain annoying, especially when we just want to get it done ASAP, otherwise we lose our train of thoughts. Git alias will allow you to do just that.
To add an alias to those long commands (or simple commonly used commands that you are lazy to write in full), you can go to your global .gitconfig, add a
[alias] section, and add the aliases that you’d like to use accordingly. The file is located in different places in different OS; C:\Users\<User Account Name> on Windows, ~/ on Unix (probably the same on Mac OS).Alternatively, if you are lazy to find it in your file explorer, `git config --global -e` will open up the file using your default text editor. |
| Adding alias to .gitconfig |
Push only the branch you are currently at
If you find yourself pushing to branches you did not intend to push, you probably installed your Git quite some time ago. To set push to only push the branch you are currently at (instead of all remote-tracking branches) change the push.default config to simple/upstream/current. For more info on each config options look here.
push, you probably installed your Git quite some time ago. To set push to only push the branch you are currently at (instead of all remote-tracking branches) change the push.default config to simple/upstream/current. For more info on each config options look here.Tips for more Advanced Users
git rebase -i before push and/or submitting a Pull Request/merging to master
If you have already been doing the good Git practices in the Beginner’s section, this will bring you up to the next level.
In the course of developing your feature branch, it is very rare that you will have a very nice commit history, as a lot of new feature will involve trials and errors. These failed attempts, however, are usually not useful to be stored in the commit history. One way to get rid of the failed-attempt commits is to use
rebase --interactive or rebase -i for short. There are quite a number of good resources covering that already (this, for example) so I do not intend to cover that again here.
Note that it is best to do this if you have not pushed your feature branch to remote, as someone else who pulled the feature branch will need to create the not-very-meaningful “merge remote tracking branch…” commit, if that other person did a
pull instead of a fetch.
git push --force-with-lease
If you are an advanced user, most probably you are quite familiar with
rebase -i above, and probably you know that you need to do push --force to replace whatever that is on remote with what you have locally. However, if you someone else happen to push to the branch and you do push --forceafterwards, that person’s work will be overwritten by your branch which does not have that commit yet.
There are many ways to solve this, but it is better to prevent it altogether, so introducing:
git push --force-with-lease. What it did is basically checks if the branch is exactly the same as what the one whopush -f expected, i.e. no extra commit from other people. It might be a good idea to set this as an alias as --force-with-lease is quite a mouthful (or a handful?) to write.
That is all for now. This post might be updated in the future (one that is in my backlog is
reflog) so do check back once in a while.Sunday, February 28, 2016
Ubuntu VMware guest stuck/hangs on boot
Apparently there is a bug in one of the recent Linux kernel update on Ubuntu running as a guest OS on VMware. To be exact, the affected kernels are versions 4.2.0-30.35, 3.19.0-51.57, and 3.16.0-62.82 (mine was Ubuntu 14.10 on Linux kernel v3.19.0-51.57). The bug report is here, and in this blog I am going to show the way to solve it (credits to the answer on this askubuntu Q&A forum).
First, you need to get into the
Advanced boot options, which you can access from the GNU GRUB menu.- Start the problematic Ubuntu VM. Hold the
shiftkey on your keyboard until you are redirected to the GNU GRUB menu. If you see the command-prompt-like log that you usually see when you boot your VM up, you missed the point where you should get redirected to the GNU GRUB menu. Restart and try again. Note that when you restart the VM sometimes the VM redirect your keyboard inputs to the host OS instead. Click the VM screen repeatedly to ensure that your keyboard inputs is sent to the guest OS. - Choose
Advanced options for Ubuntu - You will be brought to a screen where there are a list of Ubuntu you can boot into with different kernels and boot mode. Choose any that uses the Linux kernel that is not buggy (refer to the list of buggy kernels I show at the start of this post). You can just choose the default boot mode (no upstart/recovery mode).
- Congratulations! Now you have managed to boot up to your OS!
- There should be an update to the Linux kernel if you check your software updater (I was notified without needing to check manually). Just update and the problem should not occur anymore. If there isn’t any update, you can try Googling to make your VM to boot using the old Linux kernel by default for the time being.
That is all. Note that not all Ubuntu is affected; seems like only Ubuntu on VMware is affected, and only if you happened to update your Ubuntu with the buggy kernel.
Hopefully it helps!
Saturday, February 27, 2016
Integration or Isolation? That's the question
I happened to stumble upon this blog post written by a friend of mine who is also my group mate for the FBOA module I am taking in NUS this semester. The background of the post is actually that he deactivated his Facebook account sometime last year because he feels that Facebook is rather pointless and not the best choice out there as a platform to find information, share his thoughts, or to keep in touch with friends.
I agree with him that Facebook is one of the worst options out there to find information and share your thought. I mean, it is filled with people from all walks of life, and not everyone is as educated as you are, and not everyone is as thoughtful as you are by not sharing pictures of every cat or corgi they saw on the Internet, borderline explicit videos, and those "X things that only YYY understand; number N will make you shocked!" kind of posts. It can be toxic too, seeing the highlights of your friends' lives going for exchange, going on dates, outings, getaway to some exotic place etc etc, while you were there in front of your laptop in your room, living a boring life.
But those are not the main reason I am writing this post (maybe we can discuss about it another day). The post I am talking about is the first one I hyperlinked (or alternatively, here). It was about how one service is tightly integrated to another such that if one service for some reason, God forbid, is down, it will trigger a chain reaction and render us unable to access many of other services. The personal example he mentioned in the post was that he was then unable to use his Spotify because he used Facebook to sign up for his Spotify account.
That brings the question: should different services be isolated from one another? Or should they be integrated with as many others as possible? An argument for isolation is already mentioned above. An argument for integration is that it frees user from filling in the registration/sign-up form and verification hassle that is just way too common. Also, users do not need to remember yet another login ID, nickname, password, or PIN for the new platform he/she is signing up for.
There is no right or wrong answer to this question just yet. This friend of mine seems to be more inclined towards the isolation side, judging from that post. Me, I actually more inclined isolation too, but there are benefits of integration that I do not want to lose (such as no need to remember yet another password).
So what about you? You can just take my (and my friend's) post as fruit for thought, or alternatively you can express your opinion on the comment section! But then again this is just a personal blog that happens to be maintained as I am currently using it for one of my course in university, so don't expect too much discussion except perhaps with me :p.
Subscribe to:
Comments (Atom)